Figure: A sample transformation flow (flowing from left to right)
In electronic documentation, the notion of a transformation is widespread. It is a process that transforms a source document into another document, the target. This notion concerns the whole computing discipline with the advent of the XML language.
|
Quick Introduction :
Transmorpher is a program which allows the combination of
XML transformations, to apply to a set of
XML input files, and can produce different output files (html, text, xml).
The transmorpher provides two things :
|
As there are multiple computing practices, there are multiple needs for a transformation system. We motivate and present here a system that targets increased intelligibility in the expression of transformations. This need is first motivated before telling why, in our opinion, XSLT alone falls short of the objectives of simplicity and power. The requirements for such a system are then presented.
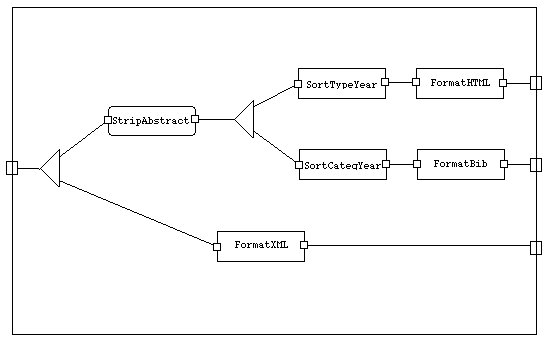
Consider someone wanting to generate part of a web site concerning bibliographic data. The source of information is a set of XML formatted bibliography documents, containing reference elements described by authors, title or abstract elements. The system aims at providing several different documents:
An HTML presentation ordered by types and year of publication,
A list of bibtex entries sorted by category, authors and year,
An HTML rendered XML presentation of the bibliography, and
The XML file of references for two particular authors.
The generation of the first three documents can be naturally expressed by the following schema in which boxes are transformations written in some transformation language (e.g. XSLT) and strip-abstract is the simple suppression of abstract elements, of elements marked as private and of mark attributes.
Figure: A sample transformation flow (flowing from left to right)
The picture represents what we call a transformation flow, i.e. a set of transformations linked by information channels. It is worth noting, that a transformation flow does not indicate if it must be processed in a demand-driven (pull) or data-driven (push) manner.
XSLT 1.0 is a very powerful technology for transforming XML documents which has been carefully designed for rendering. It has the advantage of being based on XML itself. Of course, all the manipulations that have been described in the example can be expressed in XSLT. Yet, XSLT suffers from a few shortcomings that make it both too sophisticated and too restricted at once. These shortcomings are:
Writing simple transformations (tag translation, tree decoration, information hiding such as the abstract stripping in the example) requires knowledge of XSLT even though they can be expressed in a straightforward manner by the user. There is no simple way to implement these transformations in XSLT.
If it is easy to parse an XSLT stylesheet, it is not easy to understand it because roughly the same construct with many different parameters is used for writing both simple transformations and sophisticated ones. To XPath 1.0, XSLT 1.0 adds seven extension functions, including document() for processing multiple documents. The treatment of multi-source transformations concurs to XSLT's lack of intelligibility. through this document() construct, and the strong inequality of treatment with output specification that is dealt with through an explicit output XSLT construct (although, this could change a bit with XSLT 2.0 it is not in a totally satisfying way).
As a consequence, building analysis tools is rather complicated. This is one of our deeper motivations. Analyzing transformation flows can be used for many purposes from displaying them (as in the above picture) to assessing the properties preserved by some transformations (and going towards proof-carrying transformations) and optimizing transformations.
Writing complex transformation flows involving independently designed stylesheets, multi-document dataflow and closure operation requires the use of an external environment (scripting language, shell) and compromises portability of the transformation flows.
Other pieces of work have already addressed this issue: namely the AxKit and Cocoon projects which implement pipelining of stylesheets. However, since they are concerned with demand-driven documents, they do not address the multi-output and complex dataflow issue (i.e. when a document generates several outputs that are themselves subject to independent transformations and can eventually be merged later on). These issues are important for the future XML-based information systems.
XSLT is not so limited as it may appear. But it has been designed in such a way that some powerful operations are difficult to process. A good example is the closure operation (i.e. applying a stylesheet until its application does not change the document anymore). Such an operation is very powerful and can be written very concisely. It can be used for gathering all the nodes of a particular graph (e.g. flattening a complete web site into one document can be seen as a closure operation).
For those who need these operations, they can either implement them outside XSLT (in a non portable shell) or inside XSLT (with extra contortions).
This limited power issue is sometimes described as a lack of side effects. However, XSLT provides side-effects by applying a transformation to a document and then reading that document through an XSLT specific XPath construct document() call. Moreover, recursive expressions can be written inside XSLT as shown by Oliver Becker.
In order to overcome these problems, we have started to design a system that relies on XSLT and attempts to remain compatible with it but embeds it in a superstructure. This system is Transmorpher.
Transmorpher is an environment for processing generic transformations on XML documents. It aims at complementing XSLT in order to:
describe simple transformations easily (removing elements, replacing element and attribute names, concatenating documents...);
allowing regular expression transformations on the content;
composing transformations by linking their (multiple) output to input;
iterating transformations, sometimes until saturation (closure operation);
integrating external transformations.
The guidelines of the proposal are the following:
being as compatible as possible with XSLT (by defining transformations from many Transmorpher elements to XSLT);
being portable: it is implemented in Java (as opposed to generating XSLT stylesheet and scripts which would have been an easy solution);
being open to other systems by importing any kind of stylesheet and expressing control over it;
self-contained transformation features.
In the remainder, the design of Transmorpher is presented. The next section presents its computing model involving the composition of transformations. Then, the built-in abstract basic transformations which can be handled by Transmorpher are presented. The notion of rules for expressing straightforward transformations in a drastic simplification of XSLT is detailed.
Various appendix provide useful information about setting up and developing Transmorpher
| Quick start : Instructions for getting and running transmorpher can be found in the installation guide |
The XML notation is the primary notation for Transmorpher. XML is the native format of Transmorpher.
A graphic notation has been normalized for representing Transmorpher processes. It is to be implemented by any GUI tool above Transmorpher. The graphic icons defined are presented in each section below.
You can find the graphical representation of a process (here ).
Transmorpher offers two related API. The first one is the programming API which can be used, for instance if one wants to implement a GUI system or a debugger on top of Transmorpher.
The extension Application Programming Interface for Transmorpher is intended for extending Transmorpher, i.e. defining subtypes of the components that are described in this manual. To that extent, each section below proposes the natural way to subtype components.
Both APIs are currently undocumented. They shall be presented under the API and Extension subsections of this documentation.
For developpement purposes the Java documentation of the actual Transmorpher code is made available separately.
Next chapter: Examples