Alignment Server
The goal of the Alignment server is that different actors can share
available alignments, networks of ontologies and ontology matching methods. Such a server enables to match ontologies, store the resulting alignment, store manually provided alignments, extract merger, transformer, mediators from those alignments.
We present here the architecture of the Alignment server and its first
functions as well as a short introduction to the extension of the
server by communication plug-ins. There is a tutorial showing the
server in action as well as a sample server
at https://aserv.inrialpes.fr.
For deploying your own server, see our Quick
start guide.
Architecture
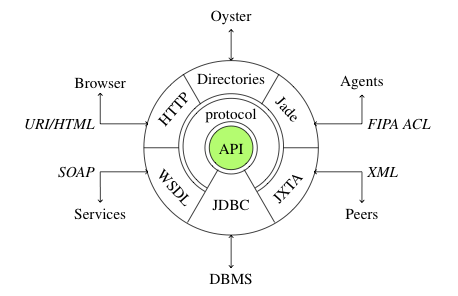
The Alignment server is built around the Alignment API (see Figure). It thus provides access to all the features of this API.
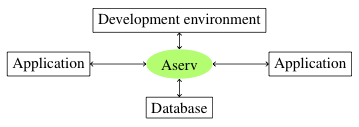
The server architecture is made of three layers (shown in the figure):
- A storage system
- providing persistent storage and
retrieval of alignments and networks.
It is used in two occasions: when explicitely calling the store
operation to store and alignment or a network persistently, and
when launching a server to load the persistency stored resources.
The storage is made through a
DBMS interface and can be replaced by any database management
system as soon as it is supported by jdbc.
- A protocol manager
- which handles the server protocol. It accepts the queries from plug-in interfaces and uses the server resources for answering them. It uses the storage system for storing results.
- Protocol plugs-in
- which accept incoming queries in a particular communication system and invoke the protocol manager in order to satisfy them. These plugs-in are ideally stateless and only translator for the external queries.
Currently, four plug-ins are available for the server:
- HTTP/HTML plug-in for interacting through a browser;
- JADE/FIPA ACL for interacting with agents;
- HTTP/SOAP and HTTP/REST plug-in for interacting as a web service.
There is no constraint that the alignments are computed on-line or off-line (i.e., they are stored in the alignment store) or that they are processed by hand or automatically. This kind of information can however be stored together with the alignment in order for the client to be able to discriminate among them.
For applications, the server can be available:
- at design time
- through invocation by design and engineering environments: It can be integrated either as an Eclipse plug-in that embarks the Alignment API or as an Eclipse plug-in that connects through web services to some alignment server.
- at run time
- through the web service access of the server
(or any other available plug-in).
The components of the Alignment server as well as the connected
clients can be distributed in different machines as presented in
the figure above. Several servers can share the same databases
(the server works in write once mode: it never modifies an alignment
but always creates new ones; not all the created alignments being
stored in the database in fine). Applications can reach the
Alignment server by any way they want, e.g., starting by using Jade and then turning to web service interface.
Alignment servers must be found on the semantic web. For that purpose
they can be registered by service directories, e.g., UDDI for web services, Oyster for ontology metadata. These directories are abstrated in a class called Directory and it is possible to add new directories to which registering Alignment servers.
Functions
This infrastructure is able to store and retrieve alignments as well as providing them on the fly. We call it an infrastructure because it will be shared by the applications using ontologies on the semantic web. However, it may be seen as a directory or a service by web services, as an agent by agents, as a library in ambient computing applications, etc.
Services that are provided by the Alignment server are:
- storing alignments and networks of ontologies, whether they are provided by automatic means or by hand;
- storing annotations in order for the clients to evaluate alignments and to decide to use one of them or to start from it (this starts with the information about the matching algorithms, the justifications for correspondences that can be used in agent argumentation, as well as properties of the alignment);
- producing alignments on the fly through various algorithms that can be extended and parametrised;
- manipulating alignments and networks of ontologies by inverting
them, applying thresholds, etc.;
- generating knowledge processors such as mediators, transformations, translators, rules as well as to process these processors if necessary;
- finding similar ontologies and contacting other such services in order to ask them for operations that the current service cannot provide by itself.
These tasks are summarised in the following table:
Most of these services correspond to what is provided by any implementation of the Alignment API.
The main principle of the Alignment API is that it can always be extended. In particular, it is possible to add new matching algorithms and mediator generators that will be accessible through the API. They will also be accessible through the Alignment servers. They can thus be extended to new needs without breaking the infrastructure.
The Alignment server can also deal with networks of alignments as
implemented in our API implementation.
A detailed presentation of how to access these functions is available
for HTML
and REST and SOAP.
Writing a protocol plug-in
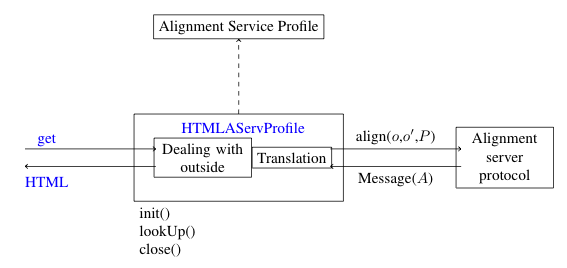
In order to implement a new communication channel as a plug-in, what has to be done is to define a new AServProfile that will invoke the AServProtocolManager with:
Message answer = manager.load(
new Message( ID, REPLY-WITH, FROM, TO, CONTENT, PARAMETERS ) );
The plug-in receives input from the outside (through its particular communication channel) and trasnmits this input to the protocol manager through such calls. It does the same thing in the opposite direction: encoding the answers so that they are understood by the outside.
This is what is dispayed in the following figure:
So, it is necessary to:
- identify in the incoming queries the value of the fields to be transmitted to the server (especially CONTENT);
- build the answer message with the same fields as those contained in the Message object. The fields have already been set so that the message is ready to be returned (in particular, the TO and FROM fields have been reversed).
A good idea to start with is to take example on the HTML interface as well as its display in order to see what is working and not. The code of this interface should be far more complex than that of the new plug-in (which should rather be translation of the messages).
The hierarchy of message types and the content of these messages are:
Message
|- Success
| |- AlignmentId -> alignment id
| |- AlignmentIds -> alignment ids
| |- OntologyNetworkId -> ontology network id
| |- EntityList -> entity URIs
| |- OntologyURI -> ontology URI
| |- TranslatedMessage -> translated message
| |- RenderedAlignment -> alignment rendering
| |- RenderedNetwork -> ontology network rendering
| |- AlignmentMetadata -> metadata
| |- EvalResult -> evaluation results
|- ErrorMsg
| |- UnreachableOntology -> faulty Ontology URI
| |- UnreachableAlignment -> faulty alignment URI
| |- UnreachableOntologyNetwork -> faulty alignment URI
| |- UnknownAlignment -> faulty alignment id
| |- UnknownOntologyNetwork -> faulty ontology network id
| |- UnknownMethod -> faulty method (Java method)
| |- NonConformParameters -> unspecified
| |- CannotStoreAlignment -> error with storage
| |- RunTimeError -> error message
Message classes returned by AServProtocolManager and their
content.
The use of message aims at facilitating the distribution of the plugs-in (if necessary) and the network of servers.
https://moex.gitlabpages.inria.fr/alignapi/server.html